Designing Large-Scale Networks Handling Billions of Transactions: A Guide for Network Engineers

Mechanical Engineer by qualification with a strong passion for technology and networking. CCIE Routing & Switching and Security (#22239, since 2008). Former Cisco TAC, HP, and Wipro. Currently focused on building free, impactful tools for India. Ongoing projects include Namohos.com, Anantaos.com, and Freefreecv.com.
Introduction
Building a network that can handle billions of transactions per second is not just a challenge—it’s an engineering marvel. From Amazon, Google, and Netflix to financial institutions and telecom giants, large-scale networks form the backbone of the digital economy. These networks must be fast, scalable, secure, and resilient, ensuring uninterrupted services worldwide.
In this guide, we will explore:
Key principles for designing scalable networks
Real-world case studies showcasing how leading companies manage massive network loads
Cost considerations when deploying high-availability infrastructures
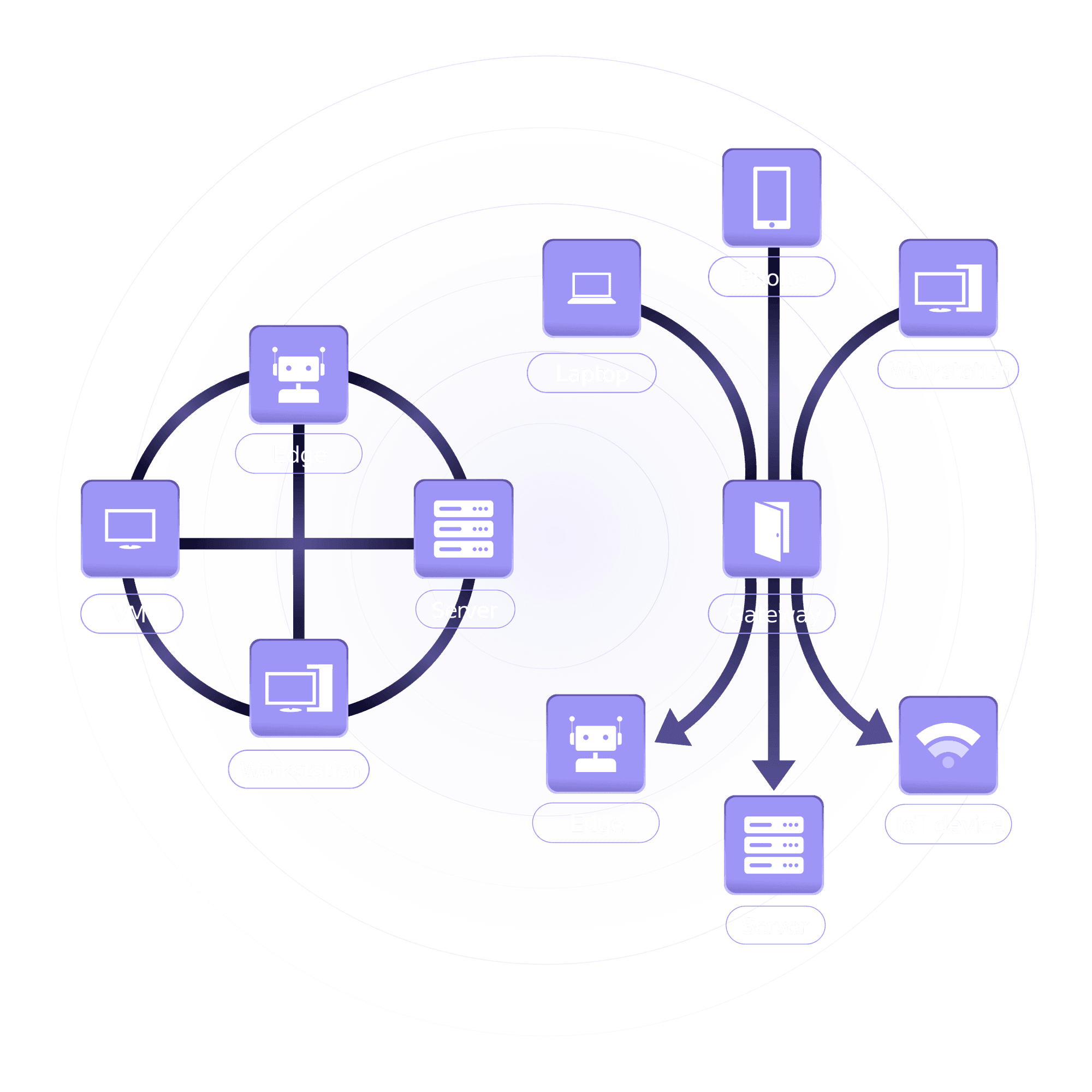
1️⃣ Scalable Network Architecture: The Foundation
A scalable network architecture is crucial for supporting massive transaction volumes. Companies like Google Cloud, Facebook, and AWS use multi-tiered architectures with redundancy and dynamic scalability.
Key Elements of Scalable Network Design:
Hierarchical Model (Core, Distribution, Access) – Ensures modular scalability.
Load Balancers (NGINX, F5, AWS ELB) – Distributes traffic efficiently.
Microservices & Containerized Deployments – Helps isolate workloads dynamically.
📌 Real-World Case Study: 🔹 Google Search Infrastructure
Uses distributed cloud computing with multi-region deployments.
Load balancing via BGP Anycast to route requests efficiently.
Handles over 8.5 billion searches daily with a 99.99% uptime guarantee.
💰 Cost Consideration:
Enterprise-grade load balancers (F5, Citrix): $50,000 - $200,000 per deployment.
Global CDN services (Cloudflare, Akamai): $5,000+ per month for large enterprises.2️⃣ High-Availability & Redundancy Strategies
Downtime can cost companies millions per hour. Redundancy and failover mechanisms are critical to maintaining uptime.
2 Best Practices for High Availability (HA):
Multi-cloud Failover – Using AWS, Azure, and Google Cloud for redundancy.
BGP Multi-homing – Connecting to multiple ISPs for internet redundancy.
Active-Active and Active-Passive Clustering – Prevents single points of failure.
📌 Real-World Case Study: 🔹 Netflix Global Network
Uses AWS across multiple regions with automatic failover.
Deploys multi-CDN architecture for global content delivery.
Ensures zero downtime during peak streaming hours.
💰 Cost Consideration:
Multi-region cloud deployments: $10,000 - $100,000 per month.
Dedicated failover routers (Cisco, Juniper): $25,000+ per unit.
3️⃣ Traffic Engineering & Optimization
Optimizing network traffic flow is key to preventing bottlenecks. Large-scale enterprises implement MPLS, SD-WAN, and BGP traffic engineering to improve performance.
Techniques for Optimizing Traffic Flow:
Quality of Service (QoS) – Prioritizes mission-critical traffic.
SD-WAN for Dynamic Routing – Reduces cost compared to MPLS.
Anycast Routing – Directs users to the nearest available server.
📌 Real-World Case Study: 🔹 Amazon Web Services (AWS)
Uses BGP Anycast to route billions of requests per second.
Implements Traffic Engineering Policies to optimize cloud workloads.
Avoids latency spikes during Prime Day sales.
💰 Cost Consideration:
MPLS network implementation: $100,000 - $1M annually for large enterprises.
SD-WAN subscription services: $500 - $5,000 per site per month.
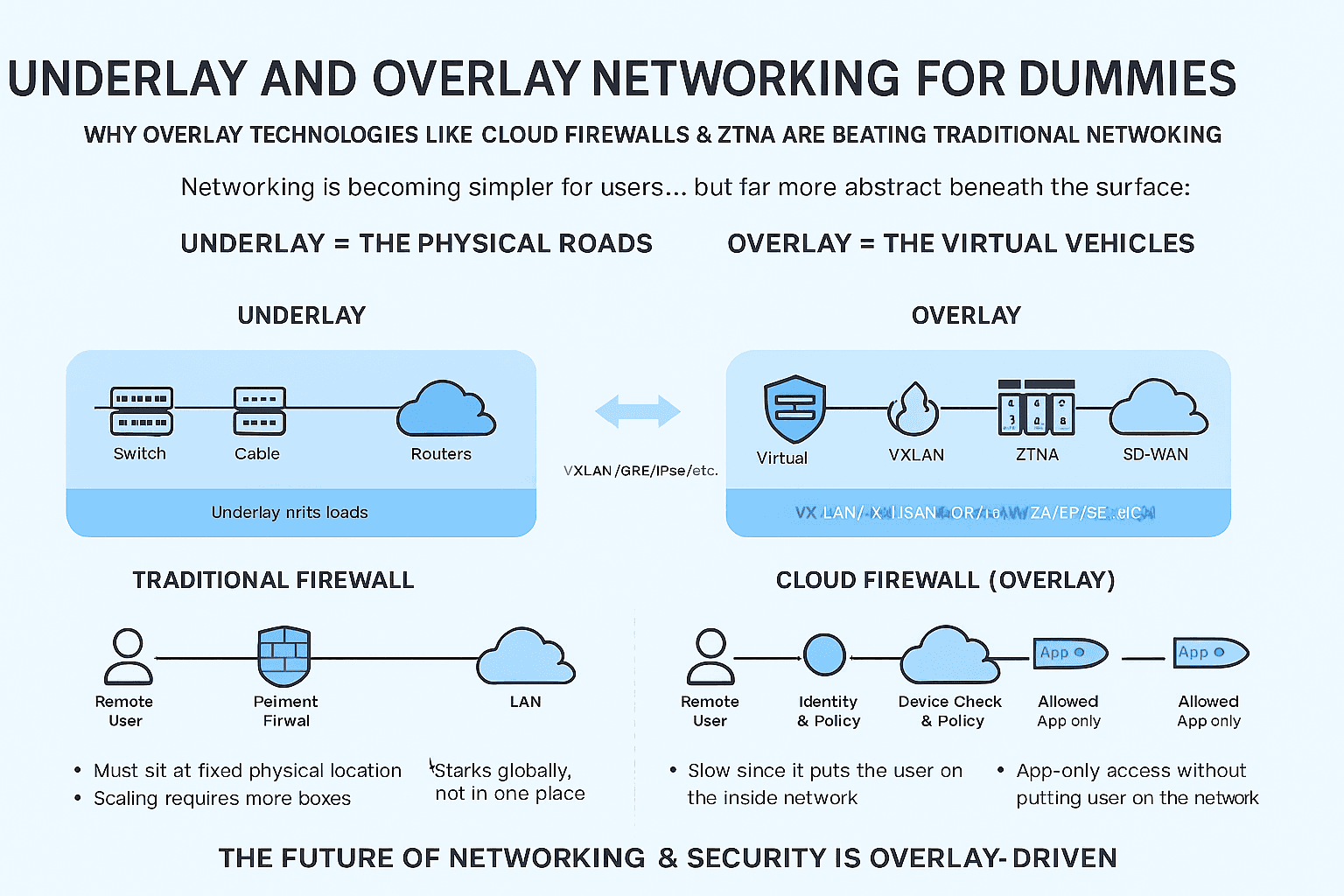
4️⃣ Zero Trust Security: Protecting Billion-Dollar Networks
Cybersecurity threats like DDoS attacks, ransomware, and data breaches pose significant risks to large-scale networks. Implementing a Zero Trust Security model ensures the highest level of protection.
Security Best Practices for Large Networks:
Next-Generation Firewalls (NGFWs) – Palo Alto, Fortinet, Cisco ASA.
AI-Driven Threat Detection – SIEM & SOAR solutions (Splunk, IBM QRadar).
Zero Trust Network Access (ZTNA) – No implicit trust; all users must authenticate.
📌 Real-World Case Study: 🔹 Financial Institutions like JP Morgan & Citibank
Invest millions in cybersecurity to protect transactions.
Deploy multi-layer firewalls & AI-driven anomaly detection.
Prevent DDoS attacks on online banking services.
💰 Cost Consideration:
Enterprise-grade firewalls: $50,000+ per deployment.
DDoS mitigation services: $5,000 - $20,000 per month.
5️⃣ Network Automation & AI-Driven Optimization
Manually managing a large-scale network is impractical. Automation and AI-powered analytics improve efficiency and reduce human errors.
Automation Tools Used in Large-Scale Networks:
Python & Ansible – Automate configurations.
Cisco DNA Center & Juniper Mist AI – AI-driven network analytics.
Self-healing Networks – AI detects and fixes faults automatically.
📌 Real-World Case Study: 🔹 Facebook’s AI-Driven Network Management
Uses machine learning to detect network failures before they occur.
Automates routing changes dynamically for optimal traffic flow.
Reduces operational costs while ensuring 99.999% uptime.
💰 Cost Consideration:
AI-driven network monitoring (Cisco DNA, Juniper Mist AI): $10,000 - $100,000 annually.
Automation tools (Ansible, Terraform): Open-source but requires skilled engineers.
Conclusion: The Future of Scalable Networks
Designing a large-scale, high-availability network is complex and requires expertise in cloud computing, automation, security, and advanced traffic engineering. The investment in redundancy, cybersecurity, and AI-driven analytics ensures businesses can support billions of transactions without downtime.
💡 Key Takeaways: ✅ Use multi-tier architectures with redundancy. ✅ Implement BGP multi-homing & SD-WAN for traffic efficiency. ✅ Deploy Zero Trust Security & AI-driven automation to prevent attacks. ✅ Optimize costs with cloud-based failover & network automation.
🚀 What are your thoughts on large-scale network design? Let us know in the comments!