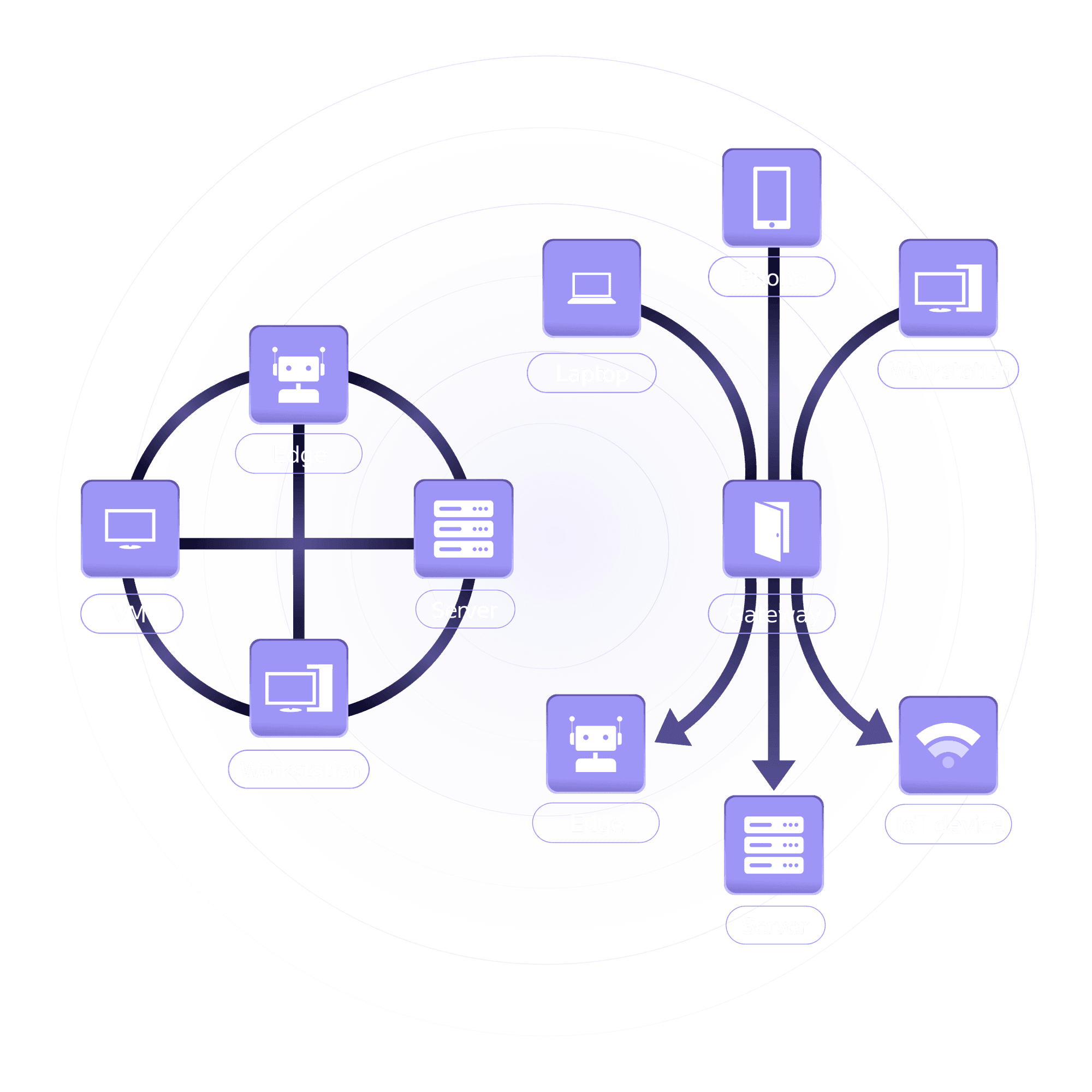
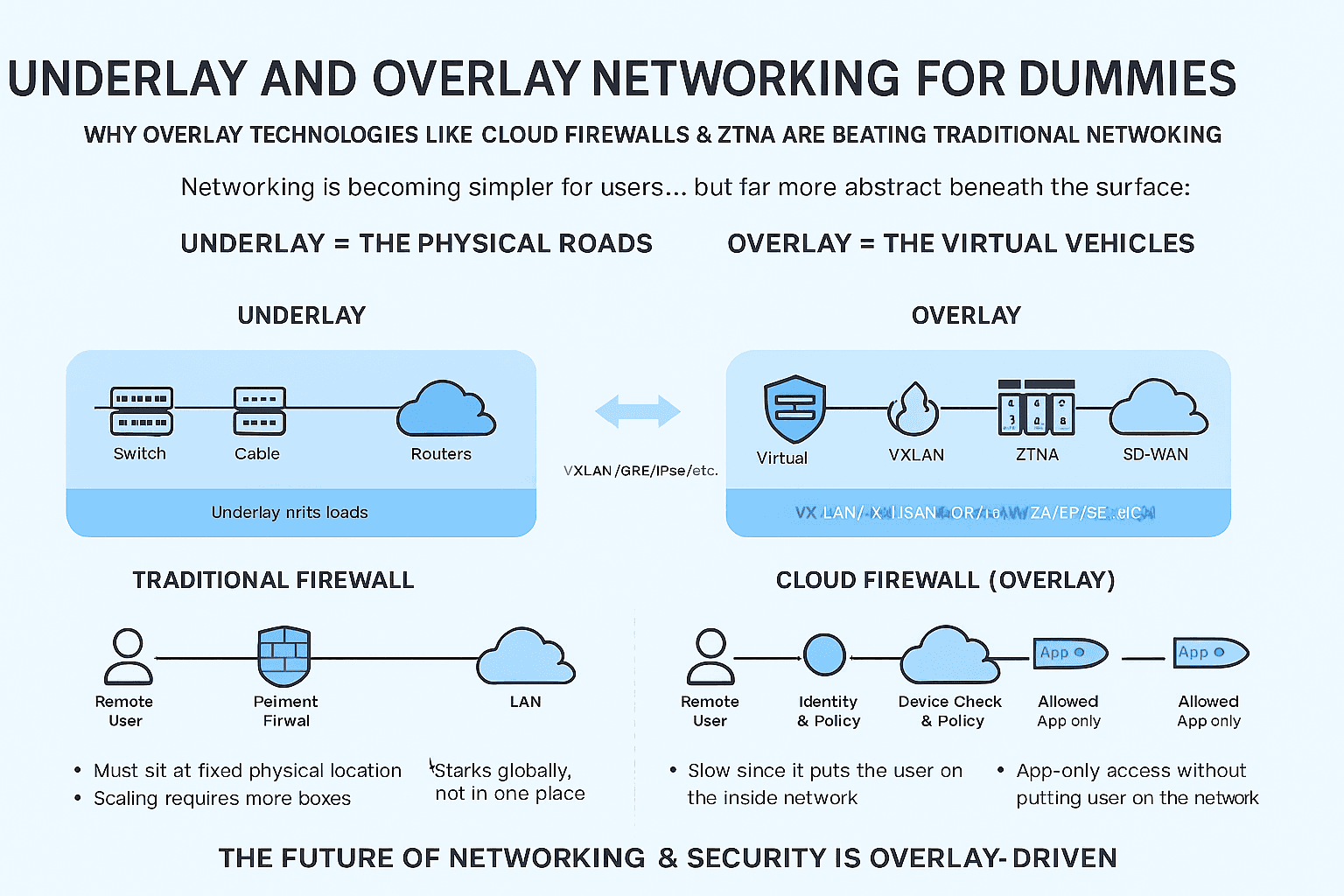
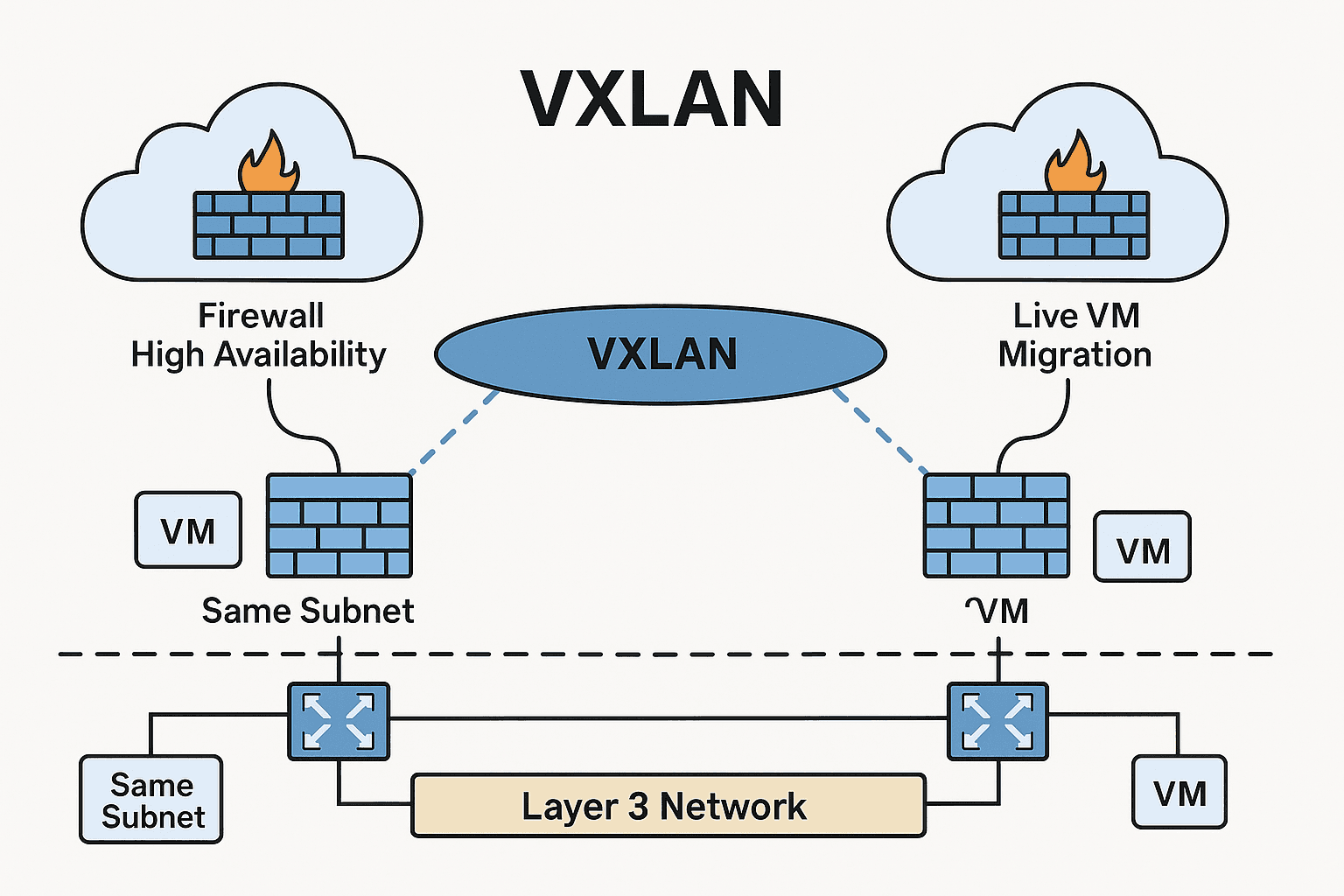
🔧 The Art of Network Design: A Must-Have Skill for Modern Network Engineers
Mechanical Engineer by qualification with a strong passion for technology and networking. CCIE Routing & Switching and Security (#22239, since 2008). Former Cisco TAC, HP, and Wipro. Currently focused on building free, impactful tools for India. Ongoing projects include Namohos.com, Anantaos.com, and Freefreecv.com.
Author: Vikas Swami, Founder – Networkers Home
Author: Vikas Swami, Founder – Networkers Home
In the evolving world of enterprise IT, one skill continues to remain critical, regardless of automation, cloud adoption, or AI-powered infrastructure: Network Design.
Designing a scalable, secure, and resilient network is more than just connecting routers and switches. It requires deep understanding, foresight, and strategic planning. For network engineers, mastering design principles is not just beneficial—it's essential for stepping into architecture and leadership roles.
🌐 What is Network Design?
Network design is the process of planning a network infrastructure tailored to business requirements—considering scalability, availability, performance, and security. It involves creating physical and logical layouts, selecting devices, designing IP schemes, and defining protocols and policies.
A well-designed network supports:
High performance
Fault tolerance
Security compliance
Seamless scalability
Operational efficiency
📌 Why Network Design Skills Matter for Engineers
While configuration and troubleshooting are vital, design thinking elevates your career. Engineers who understand design:
✅ Anticipate failure points before they occur
✅ Justify technology decisions to stakeholders
✅ Lead data center and cloud transformation projects
✅ Transition into roles like Network Architect or Pre-Sales Consultant
✅ Communicate effectively with cross-functional teams
🧩 Key Components of Network Design
Requirements Gathering
Understand business goals, user needs, traffic patterns, applications, compliance needs, and growth expectations.Logical Network Design
IP addressing strategy (e.g., VLSM, summarization)
VLANs and subnets
Routing protocols (OSPF, BGP)
Traffic segmentation and QoS policies
Physical Network Design
Device placement (Core, Distribution, Access layers)
Cabling infrastructure
Redundancy and power planning
Datacenter vs branch topology layout
Security Integration
Firewall zones
ACL planning
Secure remote access
Network segmentation for compliance (PCI-DSS, HIPAA, etc.)
High Availability & Redundancy
Dual ISP and failover
HSRP/VRRP
Layer 2 and 3 redundancy mechanisms
Cloud and Hybrid Integration
Connecting on-prem to AWS, Azure
VPN or SD-WAN architecture
Cloud-native networking principles
🛠️ Tools & Diagrams
Professional design always includes documentation and diagrams.
Use tools like:
Cisco Packet Tracer / EVE-NG (for practice)
Draw.io / Lucidchart / Visio (for diagramming)
SolarWinds / NetBrain (for automated discovery and mapping)
🚨 Common Mistakes to Avoid
Using flat networks with no segmentation
Over-engineering with unnecessary complexity
Ignoring redundancy or scalability
Poor documentation
Selecting hardware without performance forecasting
📘 Case Study: Designing a Global Enterprise Network for 2000+ Users Across 14 Countries
Designing a global enterprise network is a complex yet exciting challenge that requires balancing performance, security, scalability, and operational simplicity. In this case study, we walk you through the network design for a multinational enterprise with the following requirements:
🏢 Company Profile:
Employees: 2,000+
Presence: 14 countries (HQ + 13 branches)
Resources:
Core services in AWS and Azure
Additional colocated servers in two Tier-3 data centers
Need for secure remote access to field engineers and WFH staff
🔍 Design Requirements Overview
| Requirement Category | Description |
| User Connectivity | Stable connectivity for 2000+ users across multiple continents |
| Server Access | Secure, low-latency access to cloud and colocated infrastructure |
| Security Compliance | Adherence to GDPR, SOC2, and Zero Trust Architecture |
| Remote Access | Full-time VPN and SSO access for 500+ remote employees |
| Central Monitoring | Unified network monitoring and incident response |
🧩 Design Breakdown by Scenario
📌 Scenario 1: Enterprise Office Network (Global Branches + HQ)
Key Design Goals:
Resilient WAN design
Centralized policies with distributed enforcement
Inter-office routing and internet breakout
Design Approach:
Topology: Hub-and-spoke with dual hubs (primary in Frankfurt, backup in Singapore)
SD-WAN Overlay: Cisco Viptela with DIA & MPLS failover per site
LAN Design:
Access switches with VLAN segmentation (HR, Finance, Dev, Guest)
Distribution layer with redundant uplinks to core routers
IP Scheme: Region-wise /22 summarization for route optimization
DNS & DHCP: Split setup – HQ DNS + local caching at branches
✅ Benefits: Dynamic failover, centralized config, simplified troubleshooting, regional internet breakout
📌 Scenario 2: Hybrid Infrastructure (Cloud + Colocation)
Key Design Goals:
Redundant access to both cloud and on-prem apps
Low-latency access and secure data transfer
Design Approach:
Cloud:
AWS Transit Gateway connected to SD-WAN headend
Azure Virtual WAN with ExpressRoute fallback to IPsec tunnels
Colocation:
Tier-3 DCs (Mumbai & Frankfurt) with dual ISPs
Firewalls (Fortinet) and L3 Core Switches with redundant fabric interconnects
BGP for dynamic routing between sites and ISPs
Security:
Site-to-site VPNs with IPsec over SD-WAN overlay
IDS/IPS between cloud/DC traffic and internal LAN
✅ Benefits: Consistent access to services, segmented trust zones, cloud-burst ready infra
📌 Scenario 3: Secure Remote Access for 500+ Employees
Key Design Goals:
Always-on VPN
Zero Trust enforcement
MFA & session monitoring
Design Approach:
Client VPN: Cisco AnyConnect & Azure VPN Gateway
Authentication:
SSO with Azure AD + Conditional Access Policies
DUO MFA enforced for all privileged accounts
Access Control:
Remote employees only allowed into segmented VLANs
Privilege separation for DevOps vs Sales staff
Monitoring:
Syslog + SIEM + NetFlow export for behavior analysis
Device health check before connecting to the network
✅ Benefits: Endpoint visibility, secure connectivity, access auditing
🧠 Summary: Key Takeaways
| Component | Solution Chosen | Justification |
| WAN Connectivity | SD-WAN (Cisco Viptela) | Optimized routing, centralized control, DIA support |
| Cloud Access | AWS TGW & Azure VWAN | Native cloud routing with hybrid failover options |
| Colocation Network | BGP + Redundant Firewalls | High availability, dynamic path control |
| Remote Access | VPN + MFA + Zero Trust | Security-first design for distributed workforce |
| Management & Monitoring | NMS, SIEM, NetFlow, SNMP | Proactive alerting and compliance |
🛡️ Designing for High Availability in Network Architecture: Principles, Patterns & Case Studies
Author: Vikas Swami | Network Design Series | Networkers Home
Downtime is the enemy of modern business. In a world where milliseconds matter, even a few minutes of network failure can cost companies millions—not to mention reputational damage. That’s why High Availability (HA) is no longer a luxury—it’s a necessity.
In this blog, we’ll break down the core principles of HA in network design, explore architectural patterns, and walk through two real-world case studies that highlight how high availability saves the day.
📌 What is High Availability in Networking?
High Availability refers to designing a network so that it remains operational and accessible even when components fail. It minimizes single points of failure (SPOF) and ensures continuity through redundant paths, devices, and protocols.
🧩 Key Components of High Availability Design
| Layer | HA Technique | Description |
| Layer 1 | Dual power, cabling | Separate power circuits, cable paths |
| Layer 2 | Spanning Tree, EtherChannel | Avoid loops and provide failover links |
| Layer 3 | HSRP / VRRP / GLBP | Gateway redundancy for default routes |
| Routing | ECMP, BGP failover | Multiple equal-cost or backup paths |
| WAN | Dual ISP, SD-WAN | Transport redundancy and dynamic rerouting |
| Firewall | Active-Active or Active-Passive | Redundant firewalls with state sync |
| DNS/DHCP | Redundant services | Dual DNS servers, DHCP failover scopes |
🔐 HA vs Fault Tolerance vs Disaster Recovery
| Concept | Focus | Example |
| High Availability | Continuity during failures | HSRP, dual ISP, SD-WAN |
| Fault Tolerance | Zero downtime, no interruption | Stateful firewall clustering |
| Disaster Recovery | Post-failure restoration | Backup data center boot-up |
🛠️ HA Design Patterns You Should Know
Dual Core & Distribution Switches
Redundant L3 switches with hot-standby routing protocols (e.g., HSRP/VRRP)
➤ Used in enterprise LANActive-Passive Firewall Cluster
One firewall handles traffic; backup takes over on failure
➤ Used in perimeter security zonesDual WAN with SD-WAN
Intelligent failover between Internet links and MPLS
➤ Used in global branch designsBGP Multi-Homing
Multiple ISPs with local-pref/AS-path failover
➤ Used in data centers & public hosting environments
🔍 Case Study 1: Ensuring 99.99% Uptime for a FinTech Company
Client Profile:
500+ users in India and Singapore
Uptime SLA: 99.99%
Internet Banking & Real-time Payment APIs hosted in AWS + On-Prem
HA Design Highlights:
Dual SD-WAN routers at each site (active/active)
Two ISPs per location, BGP peering for failover
Redundant FortiGate firewalls in HA mode
AWS Direct Connect with VPN fallback
Internal DNS with failover + AWS Route53 health checks
Result:
24/7 availability achieved, with real-time failover within 3 seconds during an ISP outage. Zero downtime experienced during firewall firmware upgrades thanks to stateful sync.
🔍 Case Study 2: HA Network for a Manufacturing Plant
Client Profile:
Industrial IoT network across 2 factories
Required uninterrupted sensor-to-cloud connectivity
On-site servers and remote PLC control systems
HA Design Highlights:
Ring topology with STP & EtherChannel for link failover
Dual-core Cisco switches with HSRP gateways
Fiber + wireless backup between factory floors
Redundant DHCP + DNS servers on Hyper-V failover cluster
SD-WAN overlay to Azure for cloud analytics
Result:
Equipment and automation never went offline. During a fiber cut, network converged within 5 seconds using the wireless bridge.
⚠️ Common Mistakes to Avoid in HA Design
❌ Only buying redundant devices without planning routing/failover logic
❌ Not testing failover scenarios periodically
❌ Single points of failure in DNS, NTP, or API gateways
❌ Overlooking HA at Layer 1 (power, cabling)
✅ HA Checklist for Network Engineers
Do you have redundancy at all key layers (L2, L3, WAN)?
Are failovers stateful (firewall, VPN sessions)?
Have you documented and tested failover events?
Are monitoring tools set to alert on failover/failback?
Have you eliminated SPOFs in routing and switching paths?